Basic Introduction
Basic Introduction of TechKG
- TechKG is a large scale Chinese knowledge graph that is technology-oriented. It is built automatically from massive technical papers that are published in Chinese academic journals of different research domains.
- TechKG can be served as the datasets of many diverse applications, such as knowledge graph embedding, relation extraction, knowledge based Q&A, text classification, machine translation, named entity recognition,etc.
- In a word, TechKG is a Chinese Freebase or a Chinese YAGO!
Main Characteristics of TechKG
- First, it is the first KG that is constructed from massive technical papers.
- Second, it is the first KG that is technology-oriented and can be divided into different subsets according to the research domains.
- Third, three main characteristics can distinguish TechKG from most of existing KGs: the duplicate name issue, the extremely imbalance issue, and better application adaptability.
- In a word, TechKG is a more challenging dataset for many applications. It discovers many inherent linguistic phenomena in Chinese knowledge base, which deserve further study by researchers.
Demo
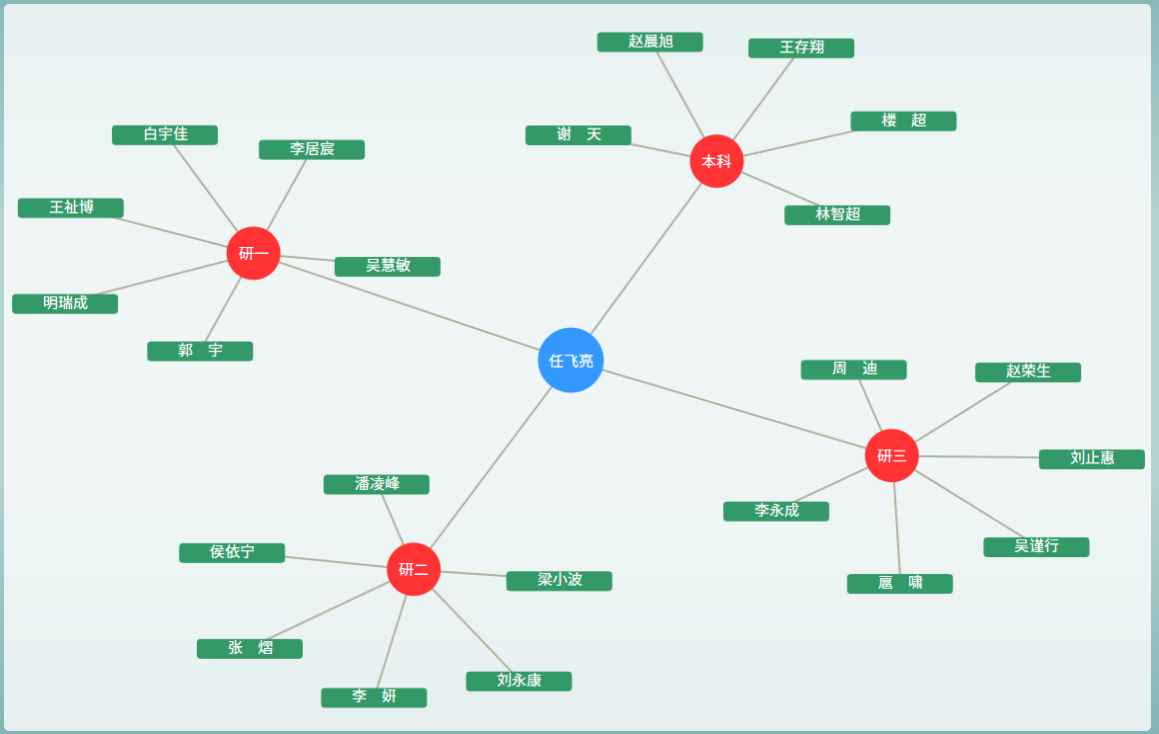
This Demo is developed by KG Research Group of NEU We provide a Demo of TechKG, which can ben used as a research tool to help users to find some basic information of a researcher or a domain termonology.
| We provide following kinds of knowledge base for download. Each knowledge base contains 38 research domains. Each research domains corresponds to a discipline. | |
|---|---|
| TechKG | The original TechKG knowledge base. |
| TechKG10 | A subset of TechKG. It contains entities that meet following two requirements. First, if the entity is a keyword, its tf*idf value must rank in top-10%. Second, each entity has at least 10 mentions. |
| TechTerm | A Chinese domain terminologies knowledge base selected from TechKG. It contains 10,000 terminologies with the highest tf*idf values for each research domain. |
| TechBiTerm | A "Chinese-English" terminology pair knowledge base selected from TechKG. It contains 10,000 bilingual translation pairs with the highest co-occurrence values in each research domain. |
| TechAbs | A knowledge base that stores papers\u2019 abstracts. It contains 100,000 randomly selected abstracts in each research domain. |
| TechQA | A dataset designed for the KBQA task. It is constructed based on TechKG-10. All the questions in it are generated by some predefined patterns. Currently, it focuses on 4 kinds of questions which are "who","what","when" and "where" |
| TechNER | A knowledge base that is based on TechTerm and constructed by a distant supervision method. It contains 30,000 randomly selected training sentences in each domain. |
| TechRE | A knowledge base that is based on TechKG10 and constructed by a distant supervision method. It contains 200,000 randomly selected training bags in each domain. Each bag contains averagely 6 sentences. |
Other Information
Project Leader
| Feiliang Ren |
Main Participants
[listing order is random]| Yining Hou | Xiaobo Liang | Lingfeng Pan | Yan Li |
| Yi Zhang | Yongkang Liu | Rongsheng Zhao | Yu Guo |
| Ruicheng Ming | Huimin Wu | ||
Paper
- More detailed information about TechKG could be found in the paper: TechKG:A Large-Scale Chinese Technology-Oriented Knowledge Graph.